机器学习
- 模型:对现实问题的数学抽象函数,以及一系列参数
- 特征:将事物的特点转化为数值,牛4条腿0翅膀,鸟2条腿2翅膀
- 数据集:在NPL中又称语料库,大量的样本集去训练数据用
- 监督学习:带有标准答案的数据集进行训练时,对模型结果进行纠正的行为。需要反复学习反复纠错,使模型更精确
- 预测:举例人名模型,通过不断学习日益精确的模型,我们给出任意一个姓名去计算他是男是女
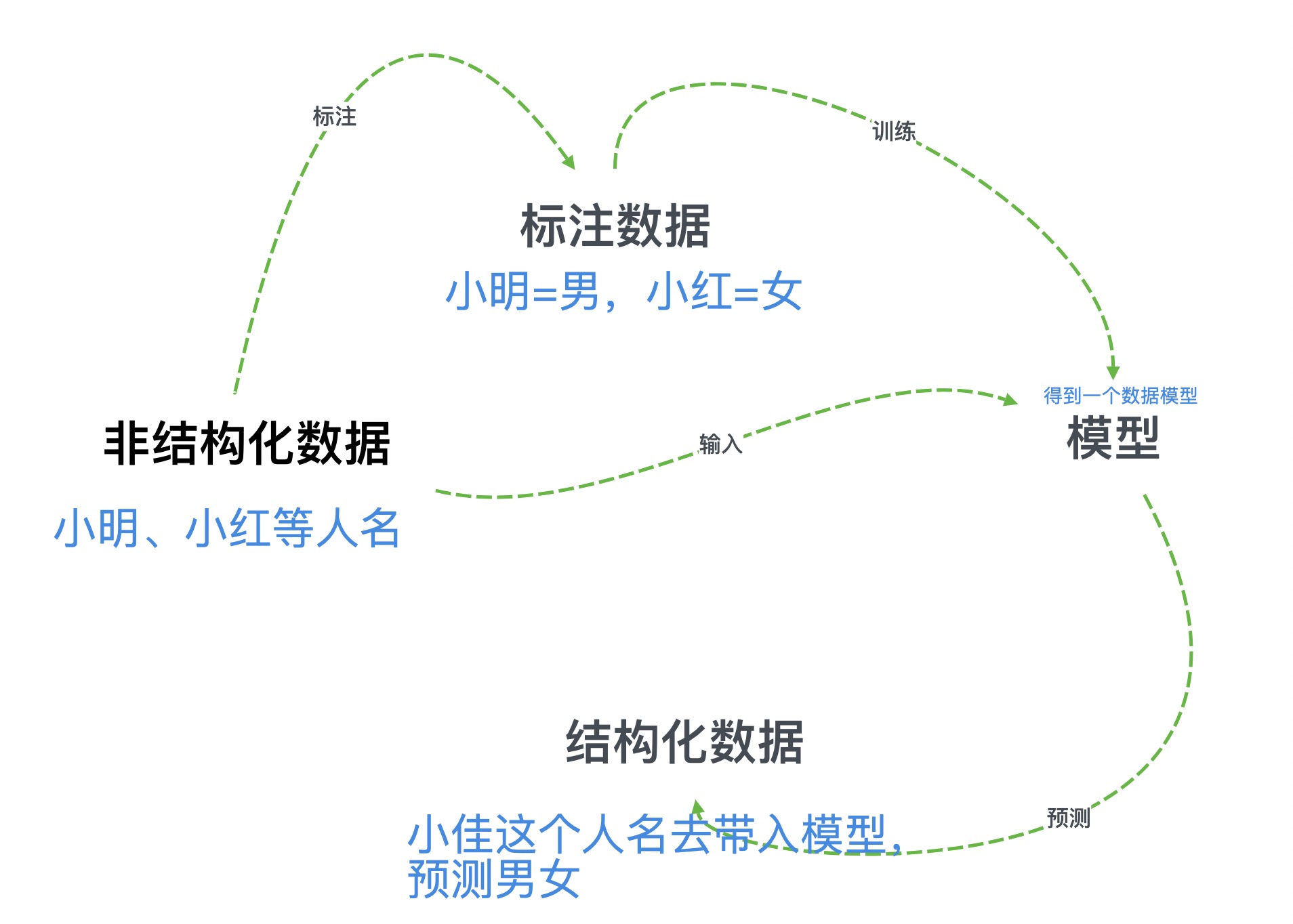
预测的准确率和模型有关,模型的准确率和样本数量是否充足、样本条件是否均衡(姓名当中男女均衡)、算法实现正确等
- 无监督学习:能够发现样本之间的联系,没有办法学习样本和答案之间的联系,一般用于聚类和降维
- 聚类:通过选择簇的颗粒度和样本的相似性决定的。比如将人名聚成2个簇,那么聚类将根据相似性将样本分为2类
- 降维:将样本点从高维空间变换到低维空间(暂时不懂)
- 半监督学习:多个模型对一个实例进行预测,得到了多个结果,如果结果多数一致,则将该实例和结果放到一起作为新的训练样本。半监督学习可以综合利用标注数据和未标注数据
- 强化学习:一边预测一边根据环境的反馈规划下次决策,比如自动驾驶、电子竞技
HanLP词典
1 | # 在这个语料库中'希望'作为动词出现了386次,作为名词出现了96次 |
如果单词本身包含空格,请以逗号分隔的使用.csv文件格式
词典加载IOUtil.loadDictionary()
完全切分
遍历文本中的连续序列,查询该序列是否在词典中
1 | 例如:今天星期五 |
依次去词典中查找是否包含分词,包含的输出
正向最长匹配(从前往后扫描)
目的:希望’北京大学’是一个词,而不是’北京’+’大学’,于是定义单词越长优先级越高
问题:如果使用了正向最长匹配的算法,’研究生命起源’====>【’研究生’,’命’,’起源’】
逆向最长匹配(从后往前扫描)
目的:’研究生命起源’====>【’研究’,’生命’,’起源’】
问题:’项目的研究’====>【’项’,’目的’,’研究’】
双向最长匹配
- 对同一语句进行正向和逆向最长匹配,若两者词数不同,则返回词数更少的那个(词数少代表词语长)
- 两者词数相同时,返回单字少的(汉语中单字词远远小于非单字词,应尽量减少结果中的单字),单字也想同时,优先返回逆向最长匹配
注意:有时候双向匹配还不如逆向最长匹配
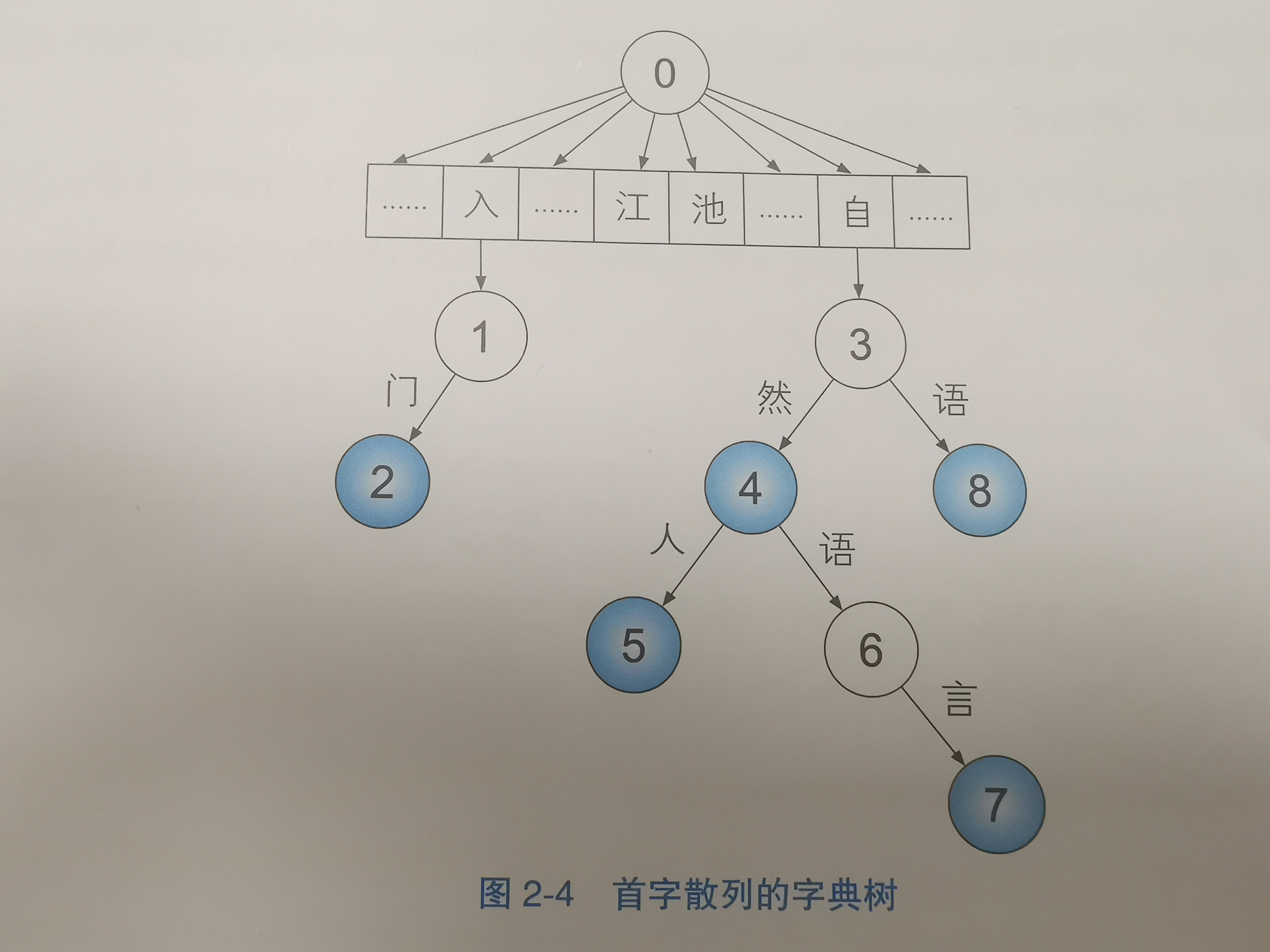
前缀树
扫描自然语言处理入门,只有自然转移成功时,自然语言、自然语言处理才会存在,如果自然本身就不存在了,就不需要匹配后面的词语了
AC自动机
前缀树的缺点是,虽然极大程度的减小了开销,但是从头一遍之后又要从第二个字开始轮询,因此思路是在前缀树的基础上为前缀树的每个节点建立一棵后缀树。
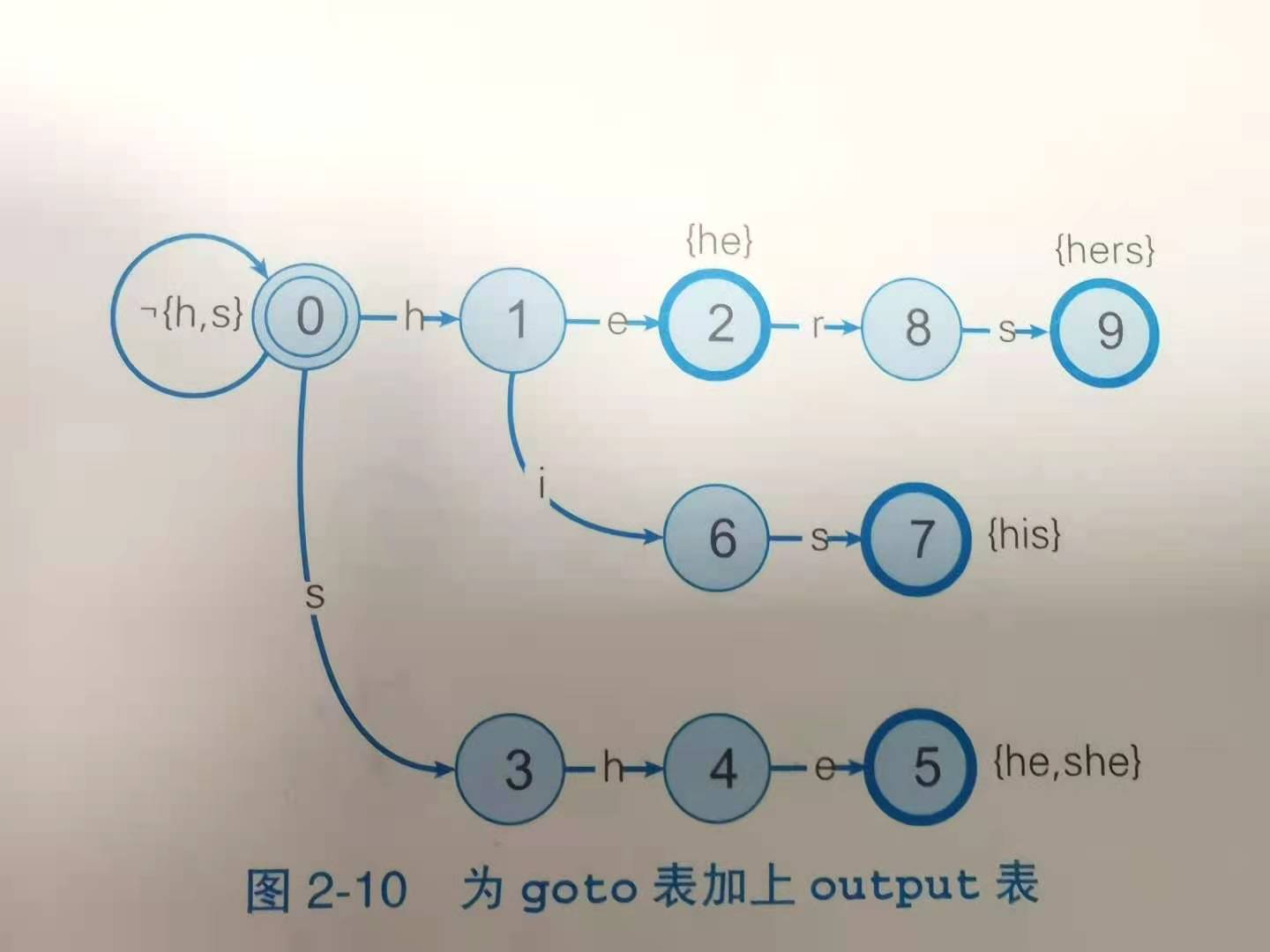
- goto表 前缀树
output表 某个单词结束时对应的模式串{he、hers、his、she},元素分为2种
- 一种是从初始状态到当前状态的路径本身对应模式串,比如2号he
- 一种是路径的后缀所对应的模式串,如5号的he
- fail表 保存状态间一对一的关系,状态转移失败后退回最佳状态(已匹配上的字符串的最长后缀的那个状态)
0345(she)---->匹配字符失败---->最长后缀为he---->对应012(he),因此状态2就是状态5fail的最佳选择,fail到状态2之后,自动机记住了he,做好了接受r的准备
0167(his)---->匹配字符失败---->最长后缀为is---->没有这条路径(要从头开始)---->次长后缀为s,对应路径为03,因此状态3是状态7fail的最佳选择
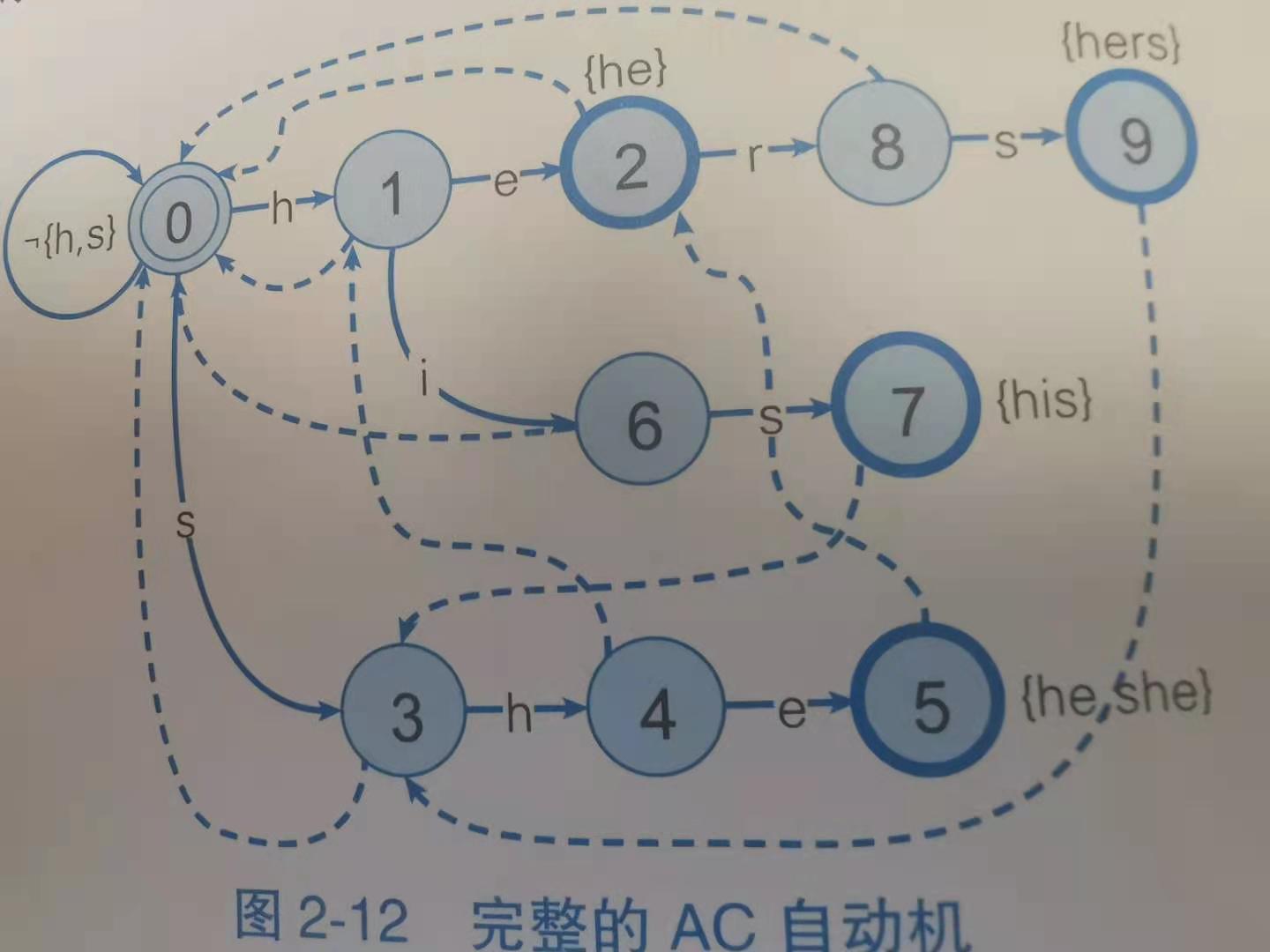
在AC机中,按照goto表转移,失败时按fail表转移,所以永远不会失败,只需扫描文本一次就能够走遍所有单词(感觉有点厉害)
基于双数组字典树的AC自动机
分句的词语如果偏长的话,使用ACDAT会快,HanLP中封装成了AhoCorasickDoubleArrayTrieSegment
当分词中有大量短模式串时,优先使用DAT即HanLP中DoubleArrayTrieSegment,否则优先使用ACDAT
准确率评测
- 混淆矩阵x
| 横坐标:标准答案,纵坐标:预测结果 | P | N |
|---|---|---|
| P | TP(预测准确) | FP |
| N | FN | TN(预测准确) |
性质:任何一个样本只属于4个集合中的一个
- 精确率——-> 预测结果中正类数量占全部结果的比率
$$
P(精确率)=TP/(TP+FP)
$$
正类指的是关注度高的,比如病人和普通人,选取病人作为正类
- 召回率——-> 正类样本被找出来的比率
$$
R(召回率)=TP/(TP+FN)
$$
- 精确率和召回率的调和平均值,综合指标,一般用这个指标来判定系统好坏
$$
F=2PR/(P+R)
$$
字典树的其他应用
- 停用词过滤 针对分词的结果,将存在于停用词典中的字去除
HanLP中词典优先级
默认为低优先级,分词器首先在不考虑用户词典的情况下由统计模型预测分词结果,最后将该结果按照用户词典合并
高优先级,首先考虑用户词典,当用户词典中的词语一定要分出来的场景(比如知识图谱的词条等),或者词语较长不容易产生歧义的前提下自行开启
1 | 句子:社会摇摆简称社会摇 |
词典中优先采取最长匹配
隐马尔可夫模型与序列标注
中文分词
{B,M,E,S}最流行的标注集
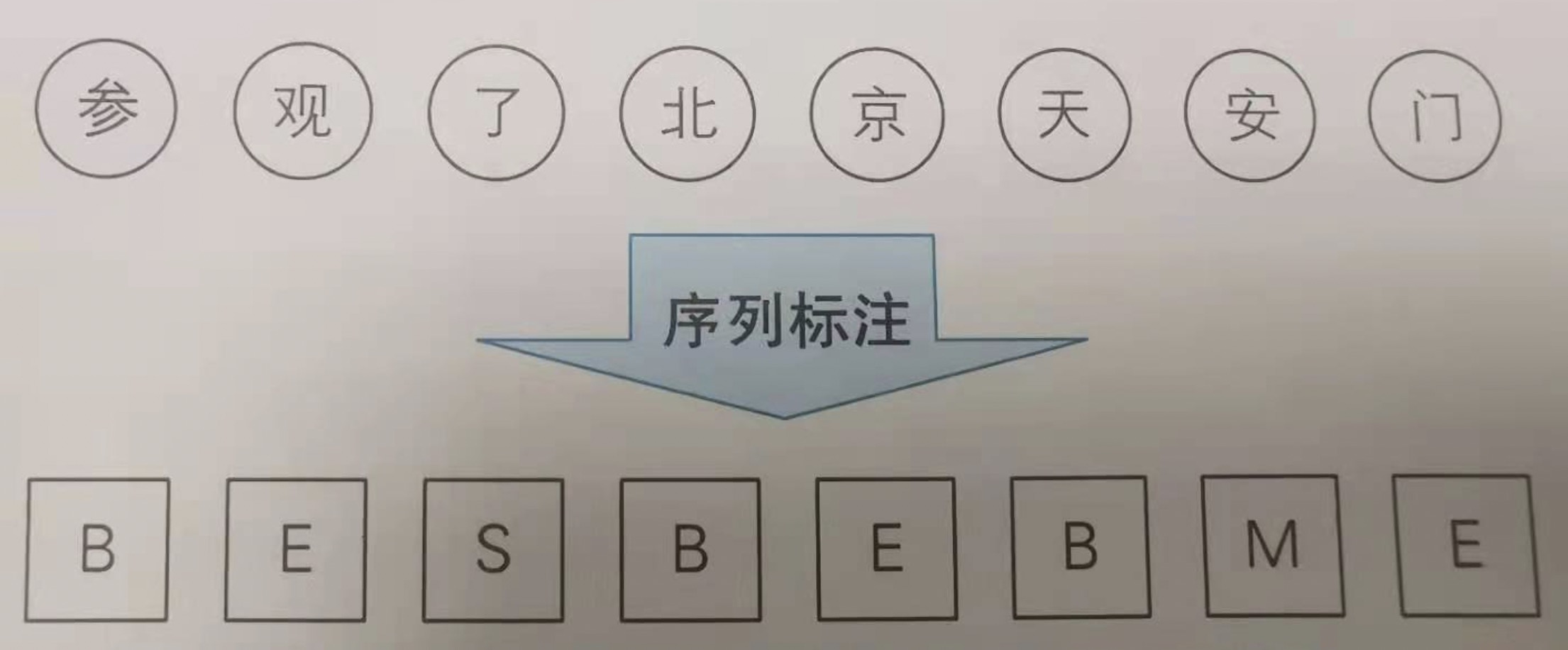
分词器将最近的两个BE标签对应区间内的所有字符合并为一个词语{参观,北京,天安门}
序列标注和词性标注
隐马尔可夫模型:一个P(x,y)概率模型,x外界可见,比如单词,y外界不可见,比如词性,需要根据单词的词序去猜测他的词性
马尔可夫假设:每个事件的发生概率只取决于前一个事件,连续多个事件串联,构成马尔可夫链
举例:1.感冒这种病和病人前一天的状态有关(假设一:任意时刻的状态只依赖前一时刻的状态,与其他时刻无关) 2.当天的病情决定当天的身体感觉(假设二:任意时刻的观测只依赖于该时刻的状态)
词性
单词的语法分类,同一类别的词语具有相似的语法性质
信息抽取
信息熵:某条消息所包含的信息量
聚类
K-Means聚类算法
原理:最小化每个向量到质心的欧拉距离的平方和为准则进行聚类
首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。
从数据集中随机选择k个数据点作为质心(数据量很大的时候,消耗大)。Hanlp中改进了聚类算法保证了下一个质心比上一个更优
对数据集中每一个点,计算其与每一个质心的距离(如欧式距离),离哪个质心近,就划分到那个质心所属的集合。
把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止。
如果新质心和原质心距离变化很大,需要迭代3~5步骤。
二分K-Means法聚类
原理:反复对子集进行二分,每次产生的簇由上而下形成了一颗二叉树结构。效率高
- 挑选一个簇进行划分,方案有多种
- 簇的体积最大
- 簇内元素到质心的相似度最小
- 二分后准则函数的增幅最大(Hanlp采用策略)
- 利用k-means算法将该簇划分为2个子集
- 重复步骤1和步骤2,直到产生足够数量的簇
自动判断聚类个数K
在二分法中,设定一个阈值A,当一个簇二分增幅小于阈值A时,说明这个簇已经达到最终状态无需再分,当所有簇都不可再分时,算法终止,此方法无需人工指定聚类簇数,但是转变成了阈值A的值难确定
分类
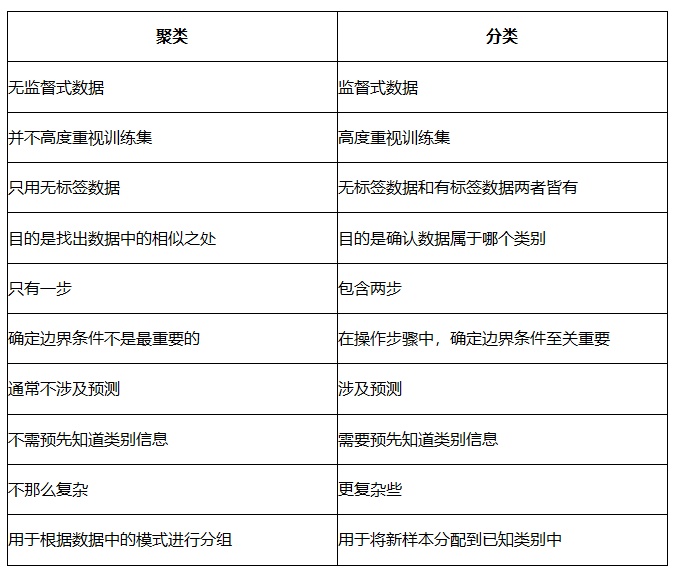
分类聚类区别:分类是你已经知道了有哪些标签,然后将这些标签绑定在不同的数据中(因为它是根据可比较的特性来分配已确定的标签,属于监督式学习),聚类是你不知道有哪些标签,根据需求分为相对应的簇
朴素贝叶斯分类器
$$
P(A|B)=P(B|A)*P(A)/P(B)
$$
P(A|B):已知B条件成立的情况下,发生A条件的概率

