几年之前有总结过Scrapy框架,这次重新系统学习,补充一些不足
Scrapy结合ES
- 第一步创建es bean
1 | # pip install elasticsearch_dsl |
- 第二步在Pipeline中将值给附上,并设置中开启该Pipeline
1 | from scrapytoscrape.scrapyto.bean import Domain |
Middleware中间件的使用
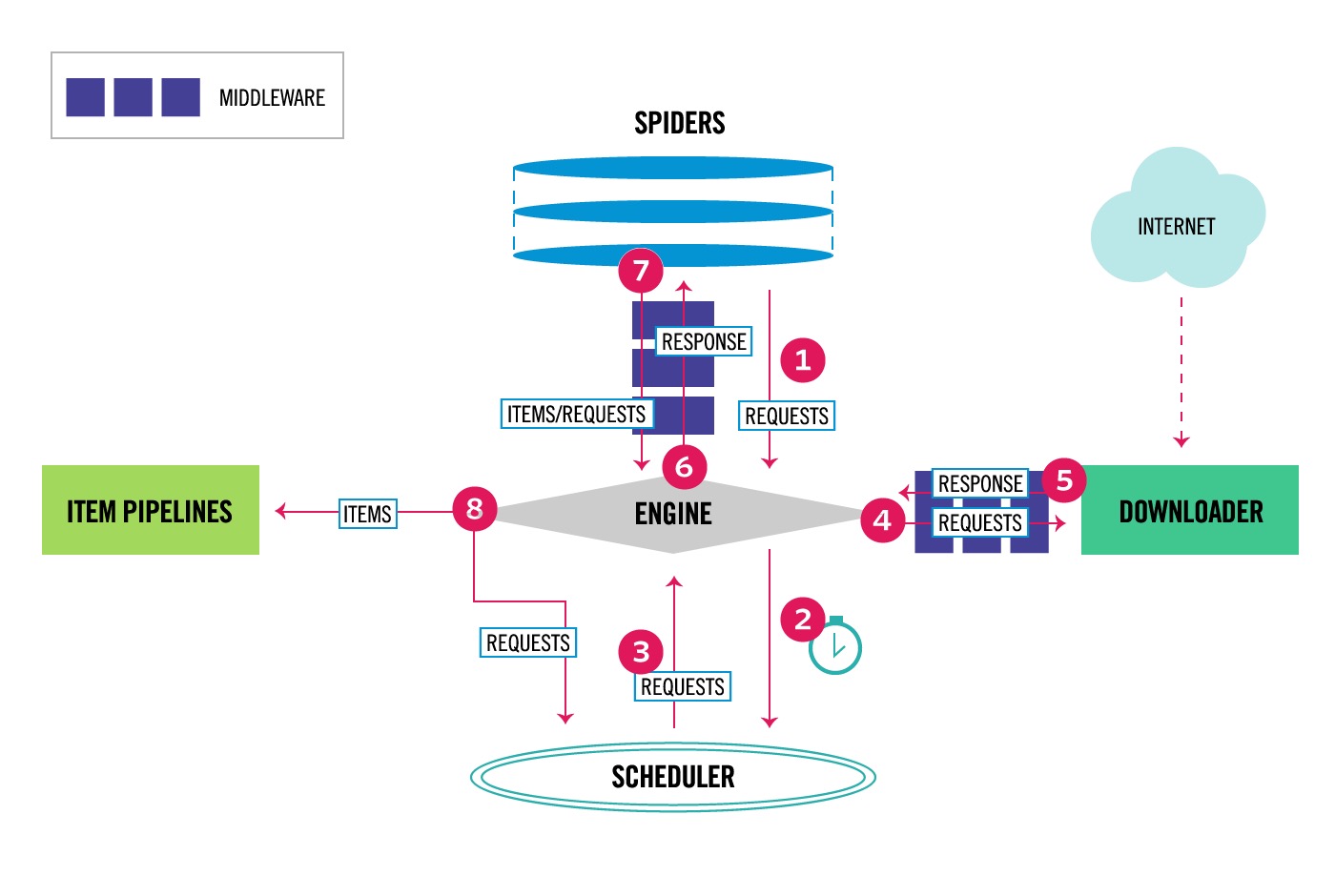
Downloader Middleware
1 | # 修改请求头、修改响应、管理cookies、丢弃非200状态码响应、丢弃非指定域名请求等 |
注意process_request方法的返回,如何不返回任何值那么剩下优先级低于它的开启的Downloader Middleware会继续执行,如果返回request那么这个请求将会处理完后发送给Engine并加回到Scheduler中,此时如果只有一个request那么它将无限循环
1 | import random |
Spider Middleware
1 | # 记录深度、丢弃非200状态码响应、丢弃非指定域名请求等 |
ItemPipeline
- 清洗HTML数据
- 检查爬取数据
- 查重
- 保存数据
1 | # 返回item则正常运行,返回DropItem则丢弃数据 |

