我使用的是Scrapy框架进行爬虫,首先我们要创建一个Scrapy项目
1 | scrapy startproject <你的项目名> |
首先确定一个网址爬虫专用网站
目的
了解网站
用chrome打开开发者工具,查看Elements

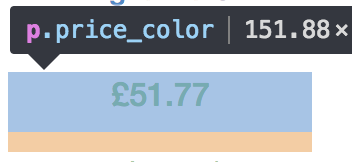


从这里我们可以看出每本书的信息都包裹在<article class="product_pod">元素中,其价格都在<p class="price_color">元素中,下一页的URL在ul.pager>li.next>a元素中
编写爬虫
在项目名称/spiders目录下新创建一个文件book_Spider.py
1 | import scrapy |
运行爬虫
cd <你的项目路径>scrapy crawl <你定义的爬虫名> -o <自定义爬下来的文件名.格式>例:scrapy crawl books -o books.csv
结果
项目结构
爬下来的其中一部分内容


