新版本ES规定,同一个index下只能有1个type
过程

Docker 启动kibana和ES
1 | docker run --name kibana -p 5601:5601 \ |
1 | docker run -p 9200:9200 -p 9300:9300 --name elasticsearch \ |
7.5.0的版本Docker安装
1 | ## 建立网络 |
1 | ## 将容器内的文件拷贝到本地 |
关于kb启动Kibana server is not ready yet问题
- 一个是初始化的问题,等半分钟即可
- 如果很长时间后还是这样,那么查看Kibana日志,如下
1 | {"type":"log","@timestamp":"2022-06-15T03:27:12Z","tags":["info","migrations"],"pid":8,"message":"Creating index .kibana_2."} |
那么此时查看
1 | http://esip:9200/_cat/indices |
如果有出现.kibana_task_manager_1这就是资源已存在的原因了,解决方法如下
1 | curl -X DELETE http://esip:9200/.kibana* |
如果开启了X-pack记得账号密码别忘
Docker配置X-pack(7.5.0版本)
1 | # 配置跨域 |
- 进入es容器,输入
./bin/elasticsearch-setup-passwords interactive手动设置密码 - 重启容器
- 如果配置了Kibana密码,则需要进入Kibana容器,打开
kibana.yml
1 | # 账户是默认的 |
- 同样的Spring配置如下
1 | spring: |
参考
Elasticsearch7.5.0安全(xpack)之身份认证
ES数据迁移
1 | 每次迁移默认100条数据,可用--limit指定条数 |
Request Entity Too Large
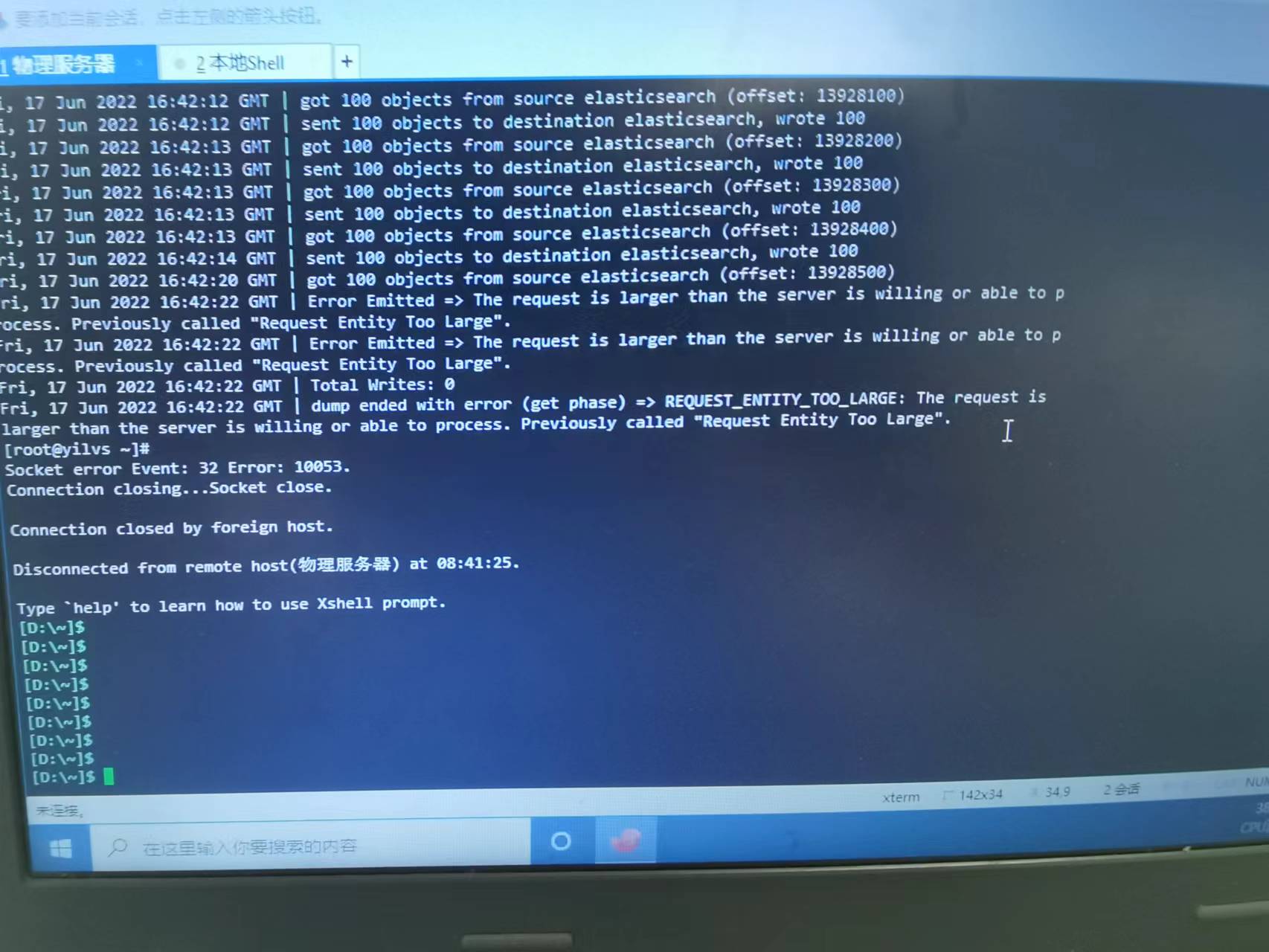
设置elasticsearch.yml中http.max_content_length值,默认为100mb
Entity content is too long [XXX] for the configured buffer limit [XXX]
配置es的buffer大小,这里设置为Integer.MAX_VALUE,可根据实际情况调节
1 |
|
ES快照创建和恢复
因为elasticdump的大数据量效率问题,所以经过了解知道了ES具备快照功能,7.5操作如下
配置
elasticsearch.yml,添加path.repo: ["快照存放的路径"],记得创建的文件夹权限设置下,否则会报错,类似于chmod -R 777 /文件夹注册快照仓库repository到ES中
1 | PUT /_snapshot/es_backup |
- 为指定索引创建快照
1 | # 快照名称这里设置为snapshot_1,需要创建快照的索引为robots_qa |
- 恢复快照
1 | POST /_snapshot/es_backup/snapshot_1/_restore |
跨服务器快照恢复
我这儿采用的方法是将源服务器的快照存放的路径下所有的文件复制到目标服务器的快照存放目录中,然后使用恢复快照
安装IK分词器
docker中挂载时发现mac会出现.DS_Store文件,导致路径出错。删除该文件
1 | Caused by: java.nio.file.FileSystemException: /usr/share/elasticsearch/plugins/.DS_Store/plugin-descriptor.properties: Not a directory |
IK分词器有2种模式:ik_max_word和ik_smart模式
ik_max_word(常用)最细粒度拆分ik_smart最粗粒度拆分
1 | POST _analyze |
扩展IK分词器
自定义my.dic,引入IKAnalyzer.cfg.xml文件中
新建索引库
1 | PUT /nba |
新增文档
1 | // ES帮你随机生成id |
查询数据
elasticsearch中match、match_phrase、query_string和term的区别
所有查询根据字段类型不同查询不同,以hello my mom为例子
- term查询keyword字段 term不会分词。而keyword字段也不分词。需要完全匹配才可以。(必须匹配
hello my mom一整个单词) - term查询text字段 因为text字段会分词,而term不分词,所以term查询的条件必须是text字段分词后的某一个(只能匹配
hello或者my或者mom才能匹配到,直接匹配hello my mom则会失败) - match查询keyword字段 match会被分词,而keyword不会被分词,需要完全匹配才可以。(必须匹配
hello my mom一整个单词) - match查询text字段 match分词,text也分词,只要match的分词结果和text的分词结果有相同的就匹配。(
hello或者my或者mom或者hello my mom都可以匹配到) - match_phrase匹配keyword字段 (必须匹配
hello my mom一整个单词) - match_phrase匹配text字段 match_phrase是分词的,text也是分词的。match_phrase的分词结果必须在text字段分词中都包含,而且顺序必须相同,而且必须都是连续的。(
hello、my、mom、hello my mom、hello my、my mom都可以匹配到,但是hello mom则无法进行匹配,因为不连续,my hello无法匹配,因为顺序相反) - query_string匹配keyword字段 (必须匹配
hello my mom一整个单词) - query_string匹配text字段 和match_phrase区别的是,不需要连续,顺序还可以调换 (任何单词都能匹配)
1 | // match_all查询所有数据 |
修改数据
1 | // 和新增类似,将新增的POST改为PUT请求,并带上id即可 |
删除数据
1 | // 根据id进行删除 |
返回列表最大数量
1 | ## ES 默认返回数量为10000,超过则会报错,此时可以在kb中设置 |
使用HanLP分词插件
要十分注意是否磁盘大小或者内存不够,如果不够会出现只读,不能进行操作
1 | [FORBIDDEN/12/index read-only / allow delete (api)] - read only elasticsearch indices |
- 分词插件下载安装
./bin/elasticsearch-plugin install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v7.5.0/elasticsearch-analysis-hanlp-7.5.0.zip
HanLP分词方式
hanlp: hanlp默认分词
hanlp_standard: 标准分词
hanlp_index: 索引分词
hanlp_nlp: NLP分词
hanlp_n_short: N-最短路分词
hanlp_dijkstra: 最短路分词
hanlp_crf: CRF分词(已有最新方式)
hanlp_speed: 极速词典分词
1 | GET /blog/_analyze |
添加本地自定义词库
docker exec -it es /bin/bash
在目录/usr/share/elasticsearch/plugins/analysis-hanlp/data/dictionary/custom中新增自定义词典:hotword.txt
修改配置文件/usr/share/elasticsearch/config/analysis-hanlp/hanlp.properties在配置选项CustomDictionaryPath后添加hotword.txt
1
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; ModernChineseSupplementaryWord.txt;hotword.txt;ChinesePlaceName.txt ns; PersonalName.txt; OrganizationName.txt; ShanghaiPlaceName.txt ns;data/dictionary/person/nrf.txt nrf;
通过logstash将mysql数据导入ES
ES官方下载logstash,配置logstash-sample.conf
1 | input { |
因为我的需求比较简单,详细参考网上
bin/logstash -f config/logstash-sample.conf执行

