
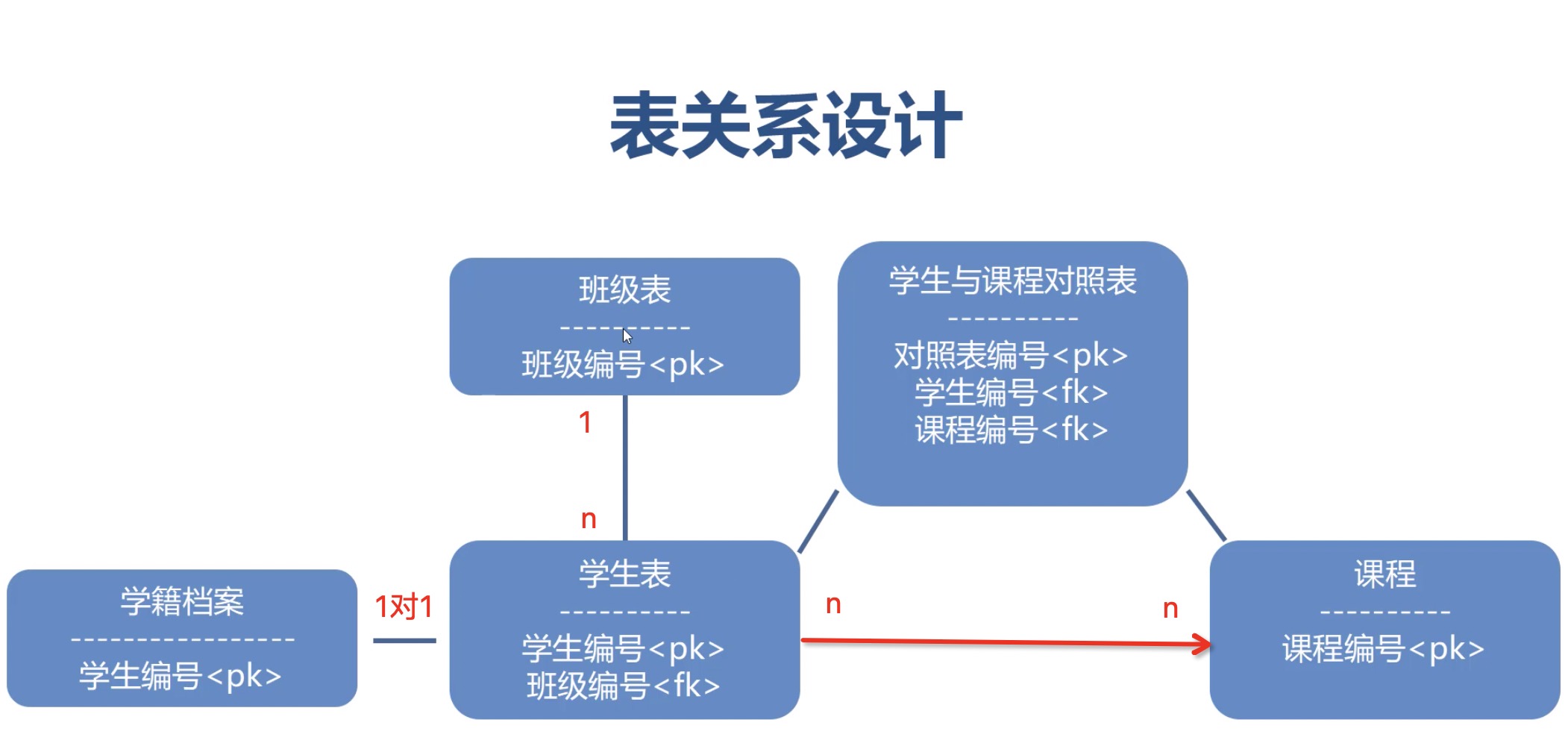
举例
- 博客文章和评论
文章:评论=1:N,所以评论表中应该持有文章表的外键
- 客户与电商订单
客户:订单=1:N,所以订单表中应该持有客户表的外键
- 用户与微信公众号
用户:微信公众号=N:N,所以需要建立第三张表去关联这两张表的主键
树形存储结构的设计
- 每一条数据添加
parent id字段,顶层节点不填留空 - 添加
path字段,方便找出上下级关系,顶层节点为”/“
1 | --查询某个节点的直接下级,pid=xx就是id=xx的直接下级 |
InnoDB
SHOW VARIABLES LIKE 'innodb_file_per_table'ON为独立表空间,OFF为系统表空间- 推荐使用独立表空间,可以多线程去读取,而且方便回收存储空间
- 独立表空间使用optimize table命令回收存储空间
行级锁、表级锁
在innodb中只有利用索引的更新、删除操作,才可以使用行级锁,不能使用索引的写操作是表锁
行级锁只的是并发更新同一行的内容时,在一方没有commit之前,另一方会出现阻塞现象,不是同一行的内容更新不受到阻塞,表级锁则是全表阻塞
注意
在实际开发中,如果遇到写操作,一定要确保更新删除语句的条件,需要能够用到索引,否则会进行锁表,程序不具备并发性
explain命令—执行计划
方便查看sql语句执行的计划,比如是否通过索引,type类型,rows大小(数值越小sql执行效率越高)
Hash索引
- 只支持精确匹配,不支持范围查询和模糊查询以及排序
- 索引选择性很低时(比如性别,男或女),不建议使用Hash索引,如果是身份证则推荐Hash索引
- 数据精准匹配时Mysql会自动生成HashCode,存入缓存,对于重复查询速度极快
索引的优化策略
- 以下前提不使用索引
is null会使用索引,is not null不会使用索引<>/not in无法使用索引- 索引选择性太差,即有太多数据符合条件,那么将会全表扫描
- where 子句跳过左侧索引列,直接查询右侧索引字段(复合索引)
- 对索引列进行计算或者使用函数(
where uid - 1 = 100索引失效,where uid = 100 + 1索引不失效)
索引优化排序
- 当排序出现了索引左侧列,则允许使用索引排序
- 左侧字段单字段排序时,索引支持升降序
- 在多字段情况下,左侧字段必须是升序,并且顺序不允许打乱
慢日志设置
mysql将记录运行慢的sql,方便后续开发人员优化sql
1 | # 开启慢日志 |
这是暂时的配置,重启mysql失效,如果想要长久开启,则去my.cnf修改
mysql分区(很少用)
案例:比如需要创建公司2014年-2020年的报表数据,我们可以采用按照年份分区的方式建立数据库
分区表的使用限制
- 查询必须包含分区列,不允许对分区进行计算
- 分区列必须为数字类型
- 分区表不支持建立外键索引
- 建表时主键必须包含所有列(所有的列组成一个复合索引当主键,所以比较少用分区)
- 最多1024分区
分库分表(常用)
ShardingSphere框架
准备
- ds0,ds1两个数据库
- 每个数据库中有
t_order_0,t_order_1两张表
1 | spring.shardingsphere.datasource.names=ds0,ds1 |
需要注意的是,mapper中关于表的书写
1 | <insert id="insert"> |

